Registered S3 method overwritten by 'GGally':
method from
+.gg ggplot2
here::i_am("notebooks/data.R")
here() starts at /Users/haziqj/github_local/house-data
# Main data sethsp <-read_csv(here::here("data/hspbn_2025-03-03.csv")) |>mutate(type =factor(type, levels =c("Detached", "Semi-Detached", "Terrace","Apartment", "Land")),tenure =factor(tenure, levels =c("Freehold", "Leasehold", "Strata")),status =factor(status, levels =c("Proposed", "Under Construction", "New", "Resale")),date =as.Date(date, format ="%d/%m/%y"),quarter = zoo::as.yearqtr(quarter) )
Rows: 31116 Columns: 18
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (10): quarter, kampong, mukim, district, type, tenure, status, agent, s...
dbl (7): id, price, plot_area, floor_area, storeys, beds, baths
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 39 Columns: 2
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (1): quarter
dbl (1): rppi
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
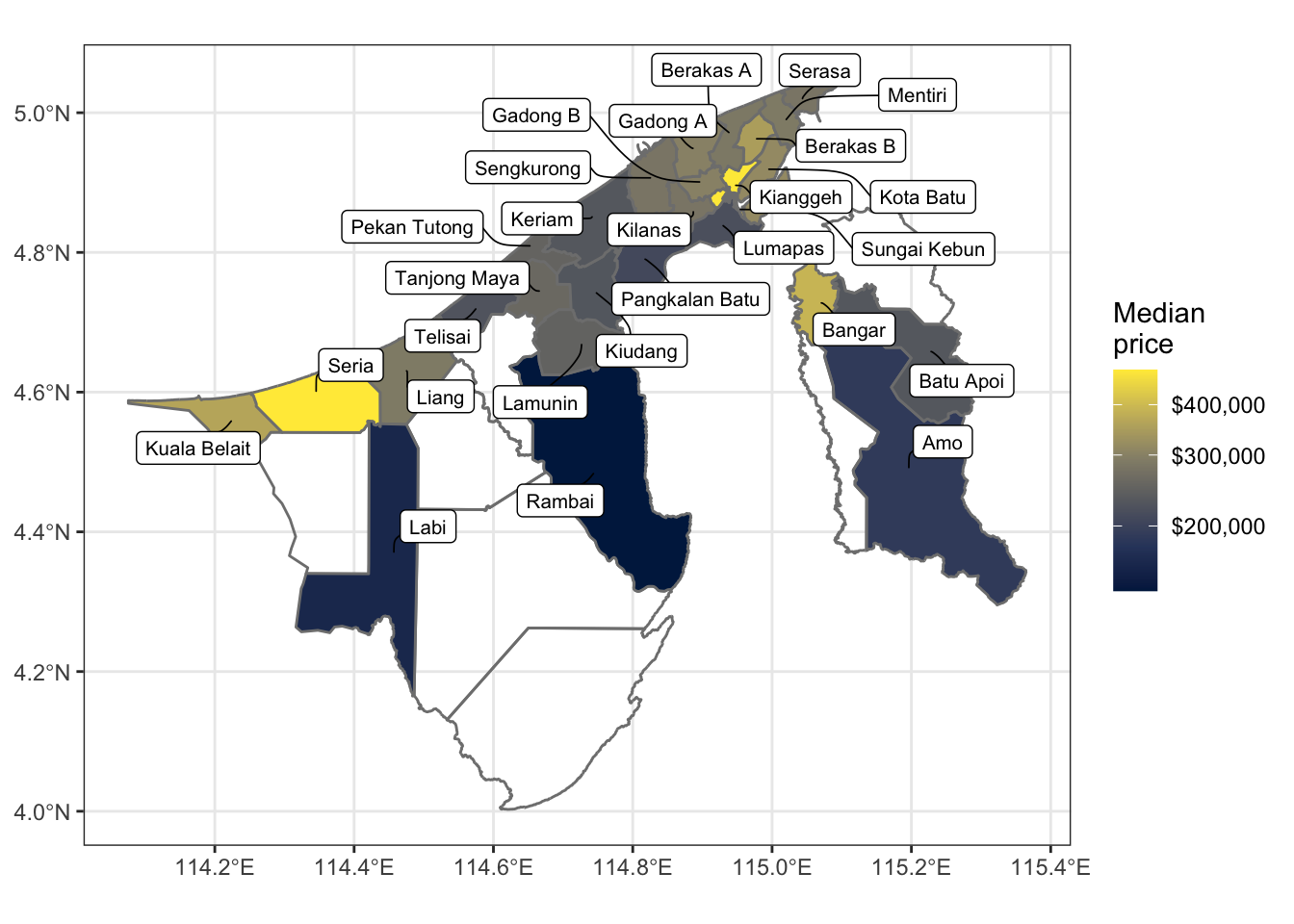
# To create median price per square foot, need to filter out "Land" types as# well as missing property types. Then create an "Overall" type.hsp_all <-bind_rows( hsp, mutate(hsp, type ="Overall") ) |>arrange(date) # Create a median price per square foot indexhsp_rppi <- slider::slide_period_dfr(hsp, hsp$date, "month", \(df) { df |>filter(type !="Land") |>drop_na(floor_area) |>summarise(quarter =first(quarter),price =median(price, na.rm =TRUE),# plot_area = median(plot_area, na.rm = TRUE),floor_area =median(floor_area, na.rm =TRUE) ) }, .before =1, .after =1) |>summarise(across(price:floor_area, \(x) median(x, na.rm =TRUE)), .by = quarter) |>drop_na(quarter) |>mutate(price_per_sqft = price / floor_area,index = price_per_sqft / price_per_sqft[quarter =="2015 Q1"], ) |>right_join(rppi, by =join_by(quarter)) rppi_mae <- hsp_rppi |>summarise(rmse = (mean( abs(rppi - index) ^1)),range =max(c(rppi)) -min(c(rppi)),mean =mean(c(rppi)),sd =sd(c(rppi)) ) |>unlist()# (rmse <- as.numeric(rppi_mae[1]))# (nmae <- (rppi_mae[1] / rppi_mae[-1])[2])# Create an sf data frame for plotting Brunei maphsp_mkm <- hsp |>summarise(price =median(price, na.rm =TRUE, trim =0.05),.by = mukim ) |>left_join(x = bruneimap::mkm_sf, by =join_by(mukim))
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
pm[6,5] <- pm[5, 6] <-NULLpm
Warning: Removed 7748 rows containing non-finite outside the scale range
(`stat_density()`).
Warning: Removed 16641 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 16641 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 14451 rows containing non-finite outside the scale range
(`stat_density()`).
Warning: Removed 10136 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 10136 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 15292 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 15292 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 4485 rows containing non-finite outside the scale range
(`stat_density()`).
Warning: Removed 14313 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 14313 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 16516 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 16516 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 11496 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 11496 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 11422 rows containing non-finite outside the scale range
(`stat_density()`).
Warning: Removed 7748 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 7748 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 14451 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 14451 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 4485 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 4485 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 11422 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 11422 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 7748 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 7748 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 14451 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 14451 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 4485 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 4485 rows containing missing values or values outside the scale range
(`geom_point()`).
Warning: Removed 11422 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 11422 rows containing missing values or values outside the scale range
(`geom_point()`).
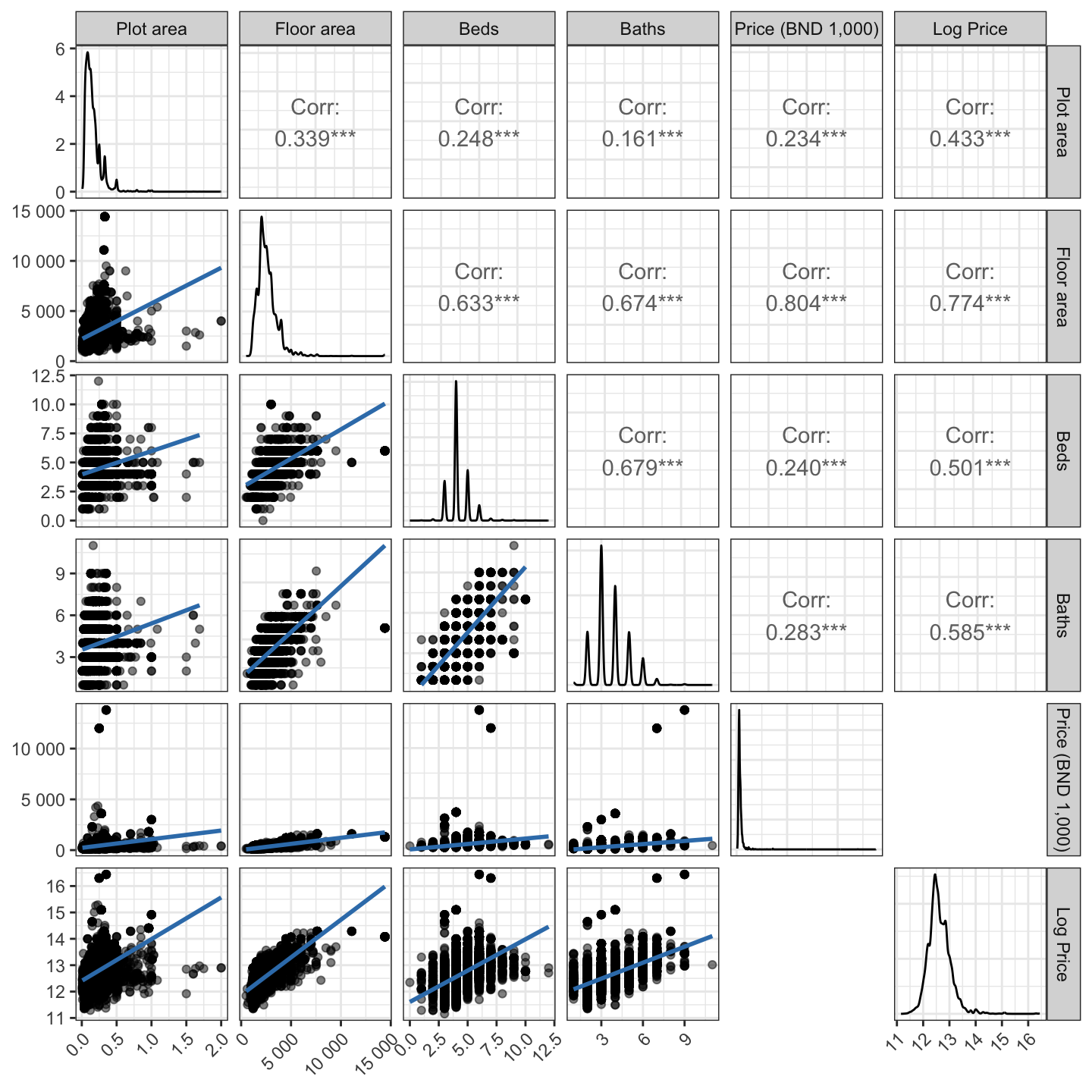
Pairwise correlation plot of continuous variables.
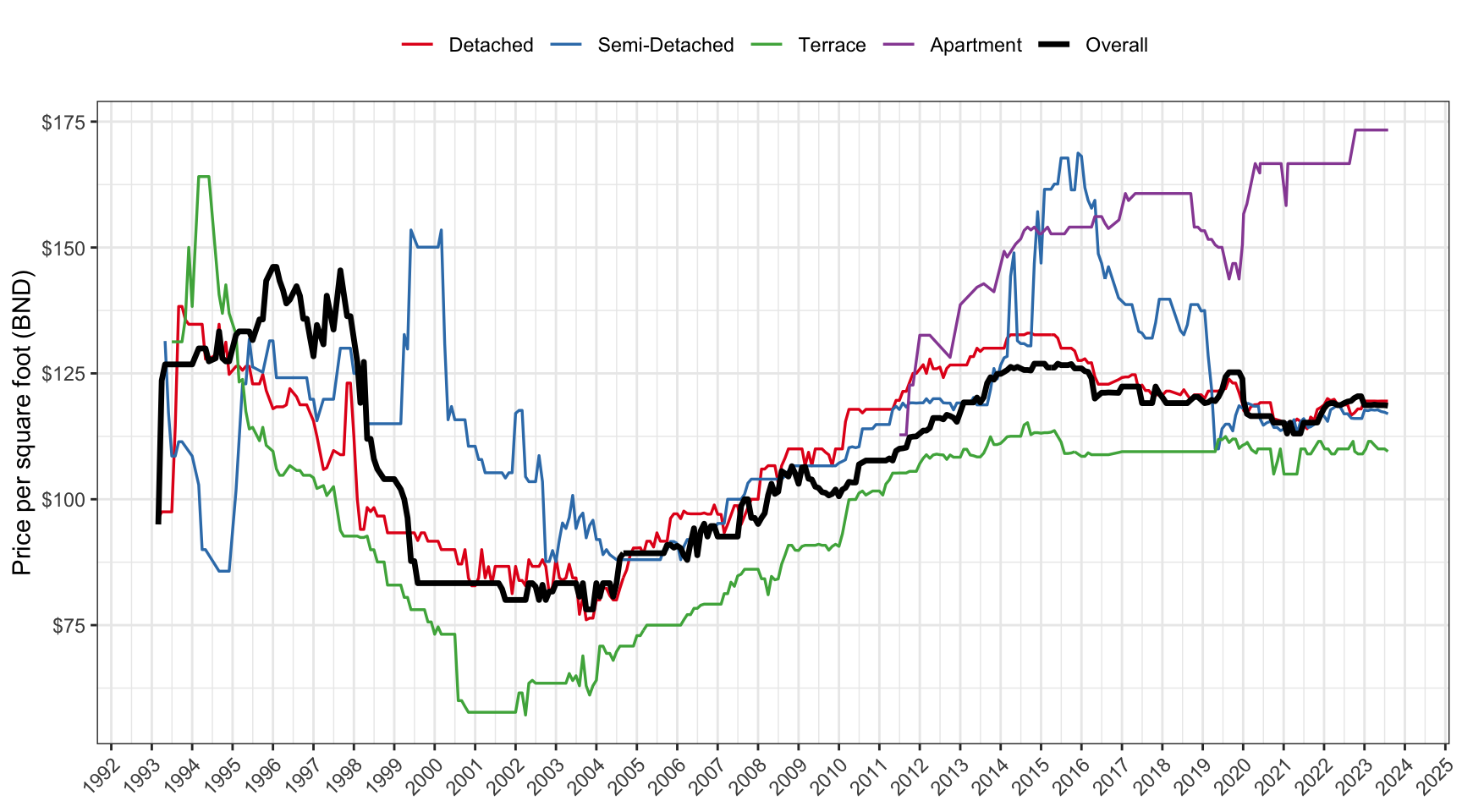
Comparison of quarterly median price per square foot indices (Median PPSF) and the official Residential Property Price Index (RPPI) from Brunei Darussalam Central Bank (BDCB).
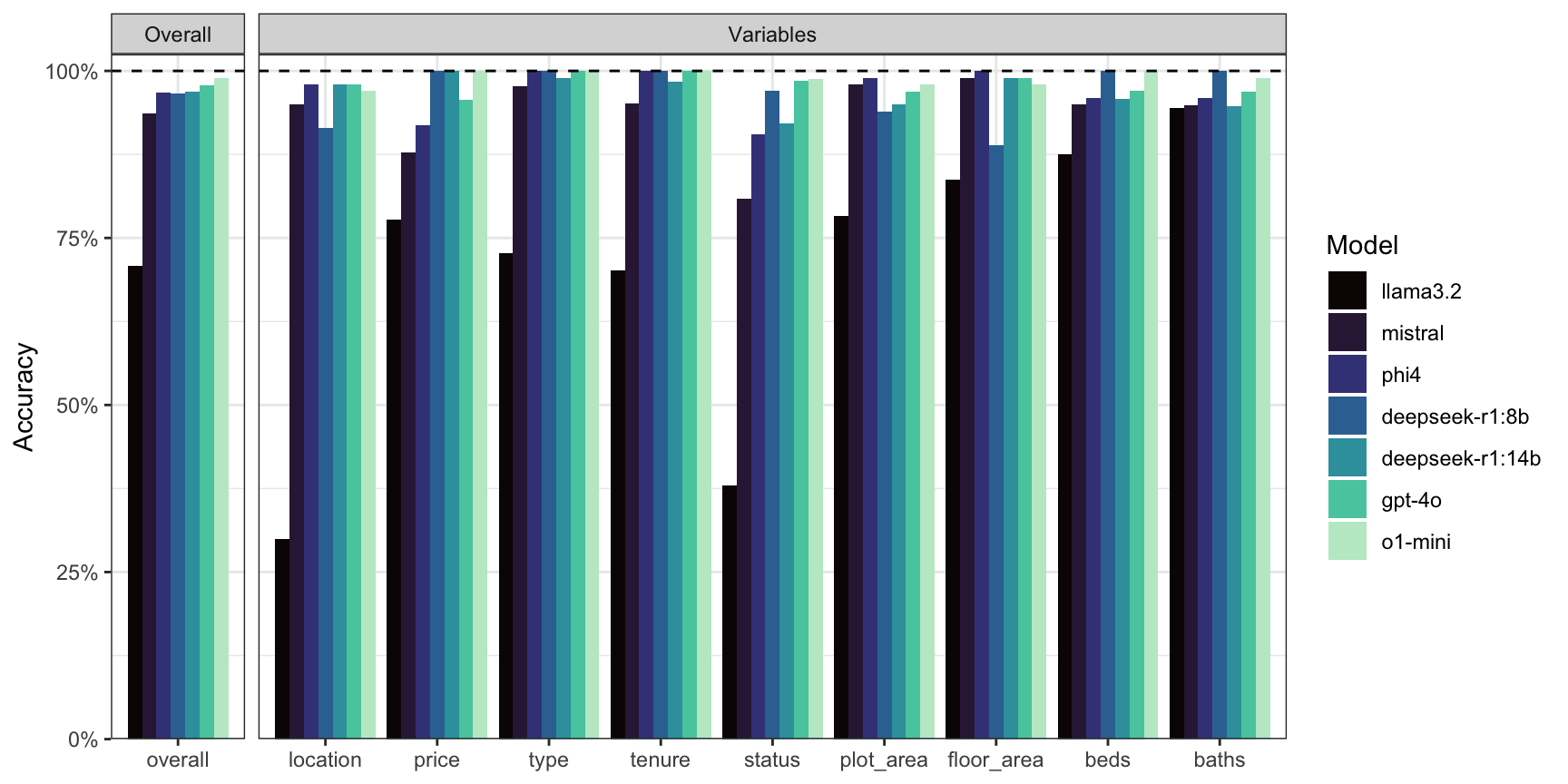
Comparison of data extraction accuracy across multiple LLM models on the test dataset. Each bar represents the percentage of correctly extracted fields for a given model.